Towards Renaming and Moving Objects in Swift Explorer
Many users, including myself, are interested in having a move function added to Swift Explorer. However this is not as trivial as it sounds to implement in a robust fashion; this claim seems to be rather counter-intuitive to several users, though.
Swift Explorer implements a sort of user-friendly “facade” to the OpenStack data structure, which presents the objects as if they were organized in a tree structure. A tree structure is quite appealing to many of us because we are all very familiar with such a structure, for all major operating systems we are using daily come with a file explorer based on trees of directories and files1, e.g., Finder, Windows Explorer, Nautilus, etc.
One of the consequences of bringing such a familiar view to the user is to provoke a certain level of disappointment and frustration when he/she realizes that some of the core functions, such as moving or renaming objects, implemented in other similar views are missing here. This disappointment, initially induced by unfulfilled expectations, might begin to intensify when realizing that the application offers no means of achieving what is taken for granted and perceived as trivial (deleting the objects and re-uploading a huge quantity of data is not cool, not cool at all, to the point of being appalling and not considered as a solution…).
In the remaining of this post, I attempt to give some comprehensible explanations on why the seemingly easy operations “rename” and “move” might somehow jeopardize the files’ integrity when naively implemented by an OpenStack client application.
For the sake of clarity let’s oversimplify things (like the Bohr model for understanding atoms: it gives a comprehensible and accessible model, but is a bit far from the reality).
A quick look at a simplistic model of a file system
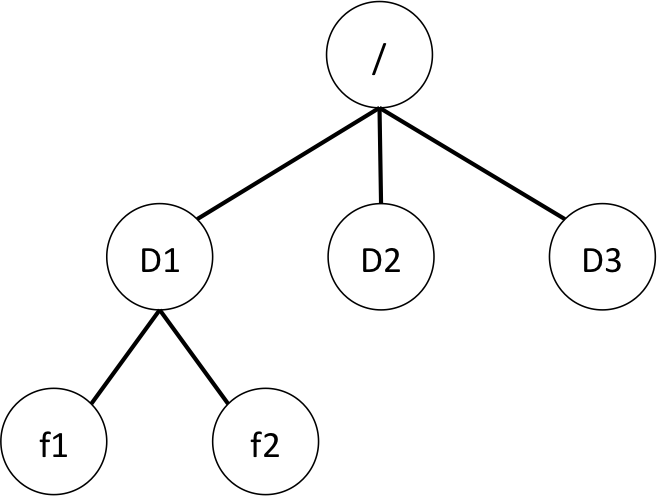
A typical computer file system can be regarded as a tree structure, in which each file constitutes a node. A file f is located in the directory D is modelled by f is a child of D, or D is the parent of f. Renaming a file is done by simply renaming the node. Moving a file consists simply in changing its parent node in the tree structure, which is as easy as, as safe as and as quick as a link swap.
Safe, here, means atomic, i.e., the data structure will not be spoiled and corrupted by an unexpected event occurring while the operation is in progress. The moving is either done completely, or not done at all.
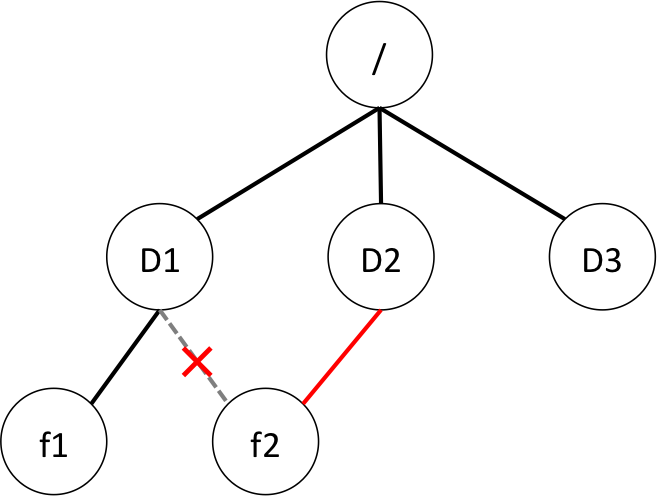
In such a model, moving a directory (which is just a particular file), even a very large one containing a great deal of subdirectories and an insanely large number of oversized files, is no different from moving a single empty file… Just a swap of a link from the current parent to the new one defining the location of the new enclosing directory.
By contrast, moving a file to another disk (i.e., to a physically different file system) may not offer the same serenity… I am quite sure that some readers have already experienced moving a large folder from a directory, let’s say, “C:\src,” to another directory located in another disk, let’s say, “D:\dest,” and after a long, long, seemingly interminable waiting time ended up with some unfortunate outcome such as having an only partially moved directory introducing some unwanted mess and triggering some unnecessary anger at the OS manufacturer (No, I did not specify any name here! What? The directories’ names used to exemplify? What about those names?).
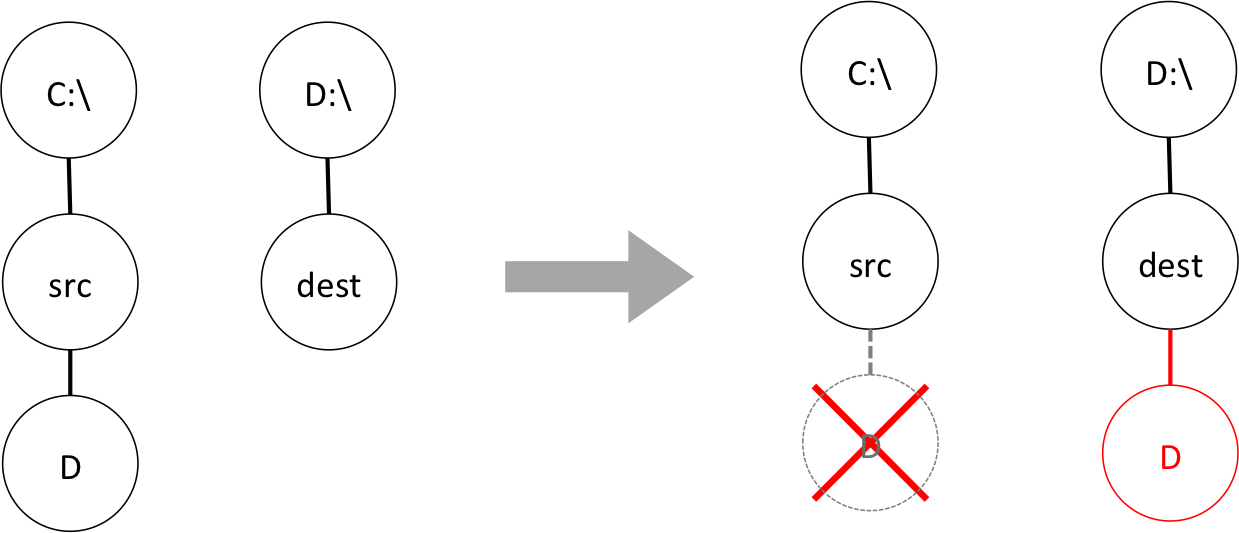
One of the difficulties here comes from the fact that moving from one file system to another involves copying and deleting files, which is in all likelihood not implemented as atomic2.
The case of the OpenStack Object Store
Unlike the OS file system, OpenStack Object Storage cannot really be interpreted in terms of a tree structure. Instead, it can be seen as a quasi-endless key-value map that extends over a large range of physically different machines. The keys are strings alphabetically ordered and the values are the binary objects (the files).

The concept of directories does not exist. Directories are simulated using the forward slash (“/”) in the key (i.e., the name of the object); this trick is described in the official documentation of OpenStack ( ). For example, the first key of the map depicted in the image above “D1/SD1/f1” can be interpreted as “the file f1 is located in the subdirectory SD1, which is under the directory D1.” Since the keys are ordered and contiguously arranged, a pseudo-directory can be scanned very efficiently to retrieve all its contents.
). For example, the first key of the map depicted in the image above “D1/SD1/f1” can be interpreted as “the file f1 is located in the subdirectory SD1, which is under the directory D1.” Since the keys are ordered and contiguously arranged, a pseudo-directory can be scanned very efficiently to retrieve all its contents.
Although such an arrangement offers many advantages for storing an arbitrarily large amount of unstructured data, it is not adequate for renaming and/or moving objects elsewhere in the structure. Moving an object from one pseudo-directory to another one would amount to renaming its key. For instance, moving the object f1 under the directory D1 would mean altering its key from “D1/SD1/f1” to “D1/f1.” However, by definition, or by construction, a key is immutable, i.e., cannot be modified.
The only alternative to rename or to move an object consists in creating a new entry in the structure by copying the object (and associating this copy to a new key), and then deleting the original entry (as suggested in the official documentation - ). This is somehow comparable to the moving of files from one file system to another one discussed in the previous section, which lacks atomicity and thus bears potential difficulties…
Besides, in the realm of OpenStack, another source of troubles surfaces from the handling of large objects (i.e., the objects that are segmented).
Concerning the copy of dynamic large segmented objects, here is a note from the official documentation ():
If you make a COPY request by using a manifest object as the source, the new object is a normal, and not a segment, object. If the total size of the source segment objects exceeds 5 GB, the COPY request fails.
Basically, it means that, in practice, the client application has to do some work to manage the copy of such objects (adding some level of complexity and thus some possible obstacles to a smooth outcome).
Let’s examine the different scenarios.
Moving or renaming a single non-segmented object
This is the easiest case, which does not pose any real difficulties. Just copy the object, and delete the source. The cost to bear is to temporarily have a duplicated object at some point in the process (thus requiring enough memory to store both copies). The risk if something goes wrong is to end with two persistent versions of the object (e.g., assuming that the object has been copied, but something unexpected happens, preventing the deletion of the original object§mdash;note that this original version could be manually deleted later on by the user).
Moving or renaming a single segmented file
Large files usually cannot be stored as a single object, and must be segmented. Such a file is then stored using a manifest object together with a set of segment objects. OpenStack currently offers two sorts of manifest objects depending on whether we want to use static large objects or dynamic large objects (). Swift Explorer relies only on dynamic large objects.

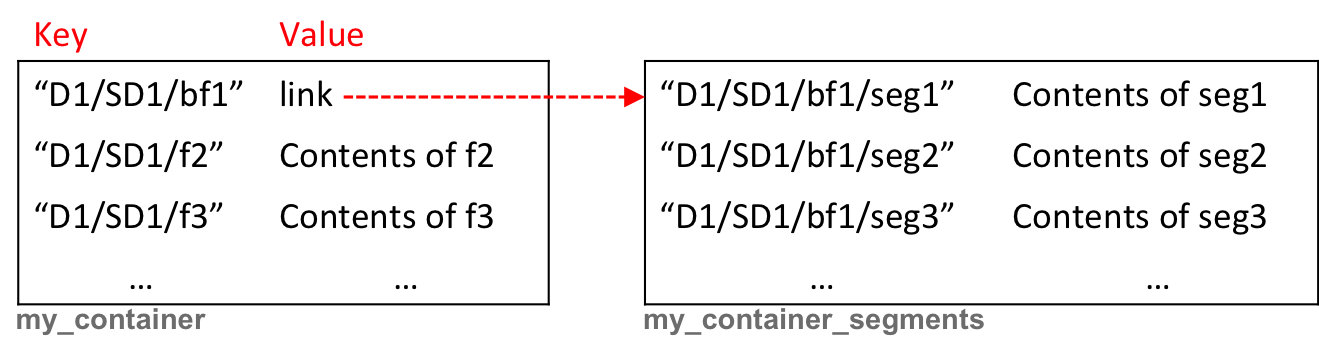
Since the segment objects are stored in a separate container3 () and are just linked by the manifest object, which then appears as a one logical large object (see the documentation ), we could just delete the manifest after having created a new one (that links to the original set of segment objects). Such an approach does not involve any copy operation, and could in some way be compared to the link swap discussed in the previous section (dealing with file systems).

One major issue, which is apparent in the illustration above, is the inconsistency introduced between the new name of the object (manifest) and the names of the segment objects. Although the segment objects should remain transparent to most of the users, leaving the inconsistency might (i.e., will eventually) cause massive problems. For example, if the user uploads a new large object with the same name as the previously moved object (the existing segments would be overwritten and thus the initially moved object would un-intendedly, and most likely immediately unnoticeably, be erased and lost for good).
Consequently, it appears to be wise and judicious to copy each segment one-by-one, and then to create a new manifest (and finally, once all these are successfully done, to delete the original manifest and associated segment objects).
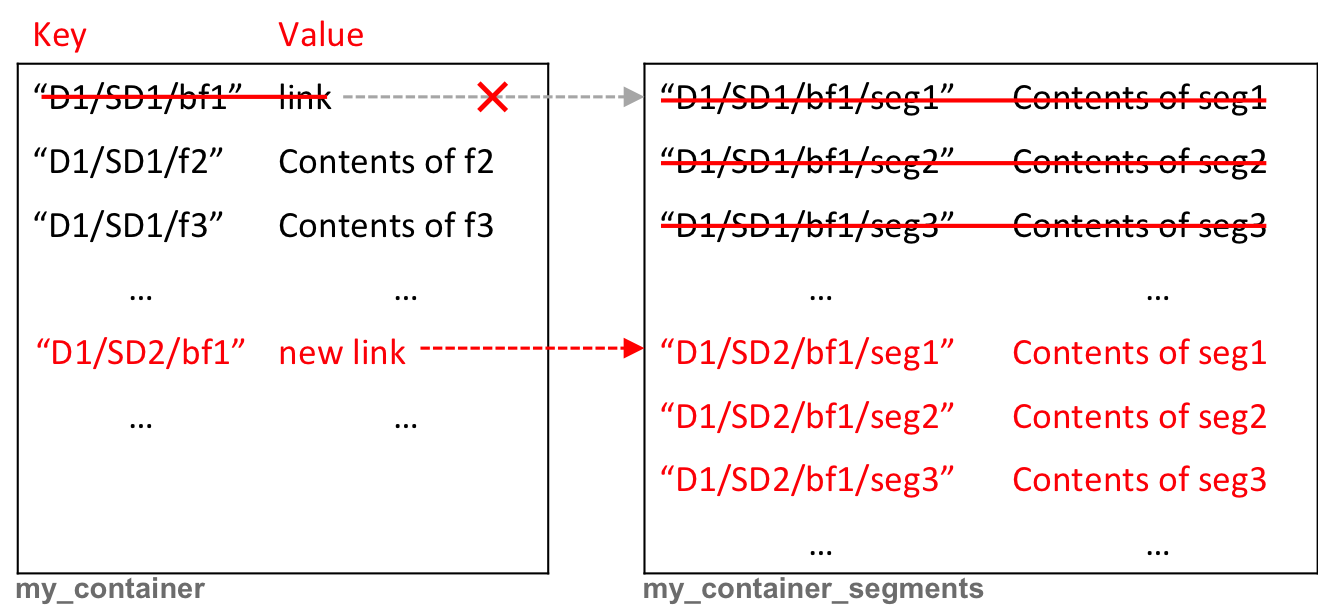
The cost is basically the same as above (with non-segmented object, except that here the object is potentially much larger), but risks are higher because some unexpected event might stop the process when only some segments have been copied. If the user does not try again a new moving of the original object to the same location as the first unsuccessful attempt, the copied segments will remain in the storage for no purpose (thus wasting space). Because the names in the segments container are explicit, the user might clean up manually (but it is definitely not really satisfactory). In other words, copying a segmented large object amounts to copying several times (as many times as there are segments), in a non-atomic way, a single non-segmented object.
A note on the hubiC’s synchronising service client application: From some discussions with the hubiC team on their dedicated forum, we could learn that they rely on an uuid instead of using the large object’s name as a base name for the segment objects; with such a way, the segment objects do not need to be copied (which is obviously a major advantage). Some disadvantages of not using the explicit name of the object include, e.g., not being able to easily identify which segments constitute the object. Furthermore, it might be harder than expected to guaranty the unicity of the uuid (ok, the probability may remain acceptably low - ). Besides, in the list of disadvantages, we can cite the non-portability of such an approach (e.g., if the client tries to move a large object that was stored using another approach, then the dangerous inconsistency between the names of the manifest and the segment objects mentioned above might surface).
Moving or renaming a pseudo-directory
We can distinguish at least two different approaches.
We could scan through the pseudo-directory and repeat the copy-and-delete as many times as necessary, i.e., for each contained object, we use one of the methods described above (either for a single non-segmented object or for a large segmented object when relevant). Note that this approach does not need to treat differently pseudo-subdirectories (for, as explained earlier in this page, directories do not actually exist, and are merely emulated via a special character in the name of objects). The scanning is really just iterating through a list (that is to say, no tree traversal method is required - unlike with a file system as presented above). The cost is more or less comparable with moving a single file. Considering the possibly large number of non-atomic operations involved, though, the risk of experiencing some troubles is quite high (e.g., ending up with a partially moved pseudo-directory, analogously to the issue described earlier, when moving folders between different file systems; except that here the mess is remote!).
An alternative approach consists in implementing what we could call a copy-all-first method. In order to minimize the risk of having an only partially moved pseudo-directory, we first copy all the objects, and only once they have been all successfully copied, we delete the original objects. Such an approach guaranties that we always have one consistent copy of the entire pseudo-directory in the storage (if something happens, we may get one copy messed up, but the other one remains intact and complete). The cost can be very high. Indeed, if the process goes smoothly, then, at some point, two copies of the entire pseudo-directory will simultaneously reside in the storage (temporarily). That is, this approach can lead to a massive data storage capacity demand. Basically, half of the storage capacity should be reserved (one can remark that this problem exists for file systems as well, as suggested in the second note below).
-
This claim may not stand that strong on the new post-PC era, but still most, not to say all, applications on mobile devices in which users need to be aware of files (i.e., select and manipulate them), are relying on tree structures. ↩
-
A quasi-atomic implementation could be achieved, e.g., relying on a copy-and-swap idiom, which is commonly used by C++ developers in order to efficiently copy large objects in an exception safe manner: the pimpl (“pointer to implementation”) idiom combined with the copy-and-swap idiom. In the context of a file system, such an approach bears a major obstacle, though, which pushes it out of consideration in practice. Indeed, the file system would have to keep half of its storage capacity free for buffering purpose… ↩
-
Bear in mind that using a separate container is not mandatory, but just a convention that seems to be widely followed. We could store the segment objects in the same container (but doing so would not constitute a good approach in practice). ↩